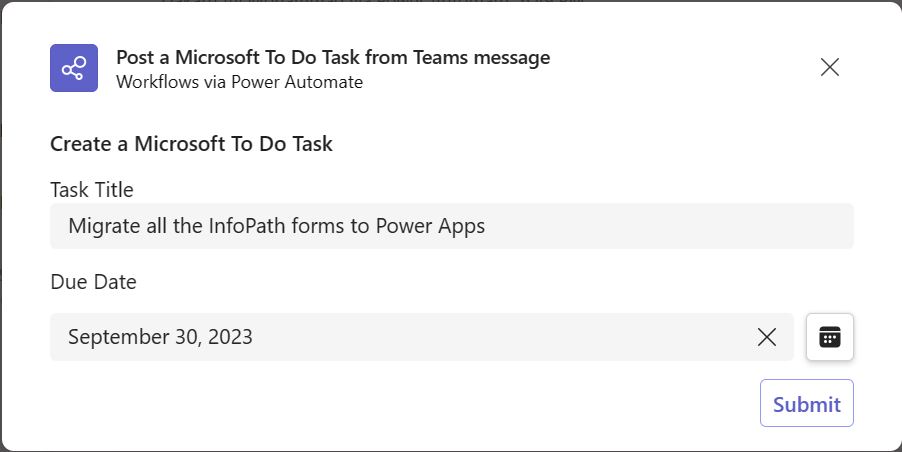
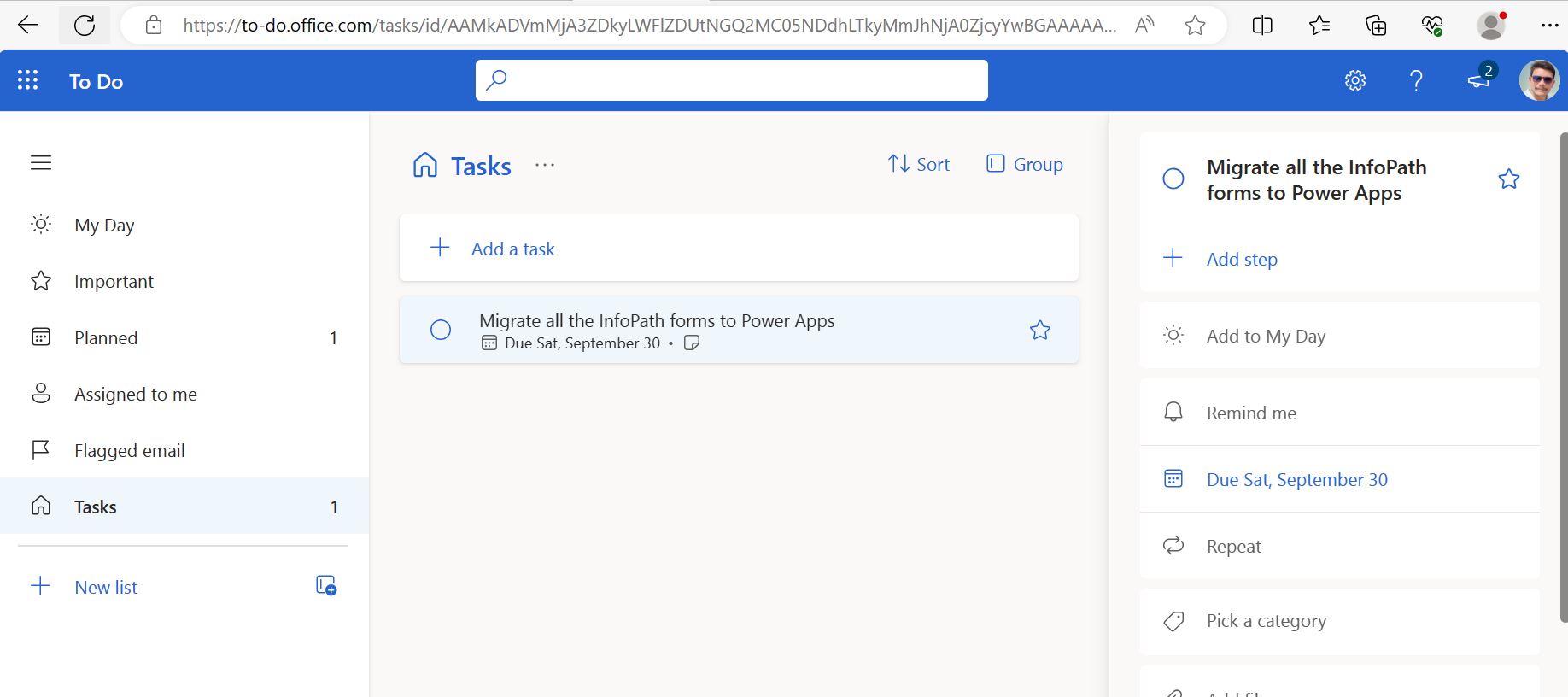
1.
Create SharePoint List that will be used as data
Input source: Invoice Request
a.
Columns: Title; Status – Both are ‘Single line
of Text’ column type
2. Create SharePoint List that will be used as
source to fetch the dynamic data for reason based on department: Rejection
a.
Columns: Department(renamed Title column)
b.
Rejected Reason (Single line of text)
c.
Populate some data in Rejection list
which will used in Adaptive Cards.
3. We will use Power Automate flow that will
automatically post an Adaptive Card to Teams Channel or Chat once the item is
created in ‘Invoice Request’ list.
4. Create a Flow and the set the trigger ‘When an
item is created or modified’
5. Add two Initialize Variables: VarSales and VarIT
6. Create two Array Variables: varSalesReasons,
varITReasons which will be using to append the data to Adaptive Cards.
7. Create another two String Variables:
SalesResponse, ITResponse which will using to capture the response that is
submitted by approver.
8. Add ‘Get Items’ actions to filter and fetch the rejection
reasons for ‘Sales’ department.
9. In Apply to each, Append all the items to an
array while incrementing.
10. These values appended to the varSalesReasons
Array which will be used later when composing the adaptive card. Expression for
both title and value:
body('Get_Sales_team_rejection_reason_from_Rejection_list')['value'][variables('varSales')]['Reason_x0020_for_x0020_Rejection']
11. Add ‘Compose’ action to compose the adaptive card message.
Below is
the JSON code that used to compose the adaptive card:
{
"type": "AdaptiveCard",
"$schema": "http://adaptivecards.io/schemas/adaptive-card.json",
"version": "1.2",
"body": [
{
"type": "TextBlock",
"text": "Sales Team Approval Request submitted by @{triggerOutputs()?['body/Author/DisplayName']}",
"wrap": true,
"id": "Request_Head",
"size": "Medium",
"weight": "Bolder",
"horizontalAlignment": "Center"
},
{
"type": "TextBlock",
"text": "@{triggerOutputs()?['body/Title']}",
"wrap": true,
"id": "Request_Body"
}
],
"actions": [
{
"type": "Action.Submit",
"title": "Approve",
"id": "Approve",
"style": "positive"
},
{
"type": "Action.ShowCard",
"title": "Reject",
"card": {
"type": "AdaptiveCard",
"body": [
{
"type": "TextBlock",
"text": "Please select a reason for rejecting the request.",
"wrap": true,
"id": "Rejection_Heading"
},
{
"type": "Input.ChoiceSet",
"choices": @{variables('varSalesReasons')},
"placeholder": "Placeholder text",
"style": "expanded",
"value": "@{body('Get_Sales_team_rejection_reason_from_Rejection_list')['value'][0]['Reason_x0020_for_x0020_Rejection']}",
"id": "Choices"
}
],
"actions": [
{
"type": "Action.Submit",
"title": "Reject",
"id": "Rejected",
"style": "destructive"
}
]
},
"id": "Reject",
"style": "destructive"
}
],
"id": "Adaptive_Card"
}
12. Post an adaptive card to Sales channel or chat and wait for
response.
13. AC will be posted to Sales team
channel once the request is submitted in the list. And it will look like below
14. Approver can Approve or Reject. If the
approver clicks Reject, then department specific rejection reasons will show up
on the AC.
15.
Let’s capture the AC Sales team response
in varSalesResponse variable.
@{body('Post_an_Adaptive_Card__and_wait_for_a_response')['submitActionId']}
16.
Once we receive the response, update
the same in the ‘Invoice Request’ list.
17. Note: I have created below two columns(as flags)
to skip the infinite trigger loop in update item action.
a. SalesApprovalSent – Default value is: No
b. ITApprovalSent – Default value is: No
18.
If the Sales team approves the
request, it will then be routed to IT team for further approvals.
19. For this add a condition to verify the
outcome of the Sales team approval response(varSalesReponse).
20.
Repeat the steps from 8 to 17 for IT
approval process and replace Sales with IT.
21. If the Sales Approver approve the
request in 14th steps then it will be routed to IT team approvals
and below the AC will be posted in the Sales team channel or chat.
22.
Capture the IT team approver response
in varITResponse variable.
@{body('Post_an_Adaptive_Card__and_wait_for_a_response_3')['submitActionId']}
23.
And then update the status in the ‘Invoice
Request’ list.
24.
Note: I have added the below
expression in the ‘When an item is created or modified’ trigger conditions.
@not(equals(triggerOutputs()?['body/SalesApprovalSent'],'Yes'))